Deepseek - The Six Determine Challenge
페이지 정보

본문
Aside from these progressive architectures, DeepSeek-V2 additionally follows the settings of DeepSeek 67B for other particulars corresponding to layer normalization and the activation operate in FFNs, unless specifically acknowledged in any other case. Later, on November 29, 2023, DeepSeek launched DeepSeek LLM, described as the "next frontier of open-supply LLMs," scaled as much as 67B parameters. The latest iteration, DeepSeek V3, is a 671-billion-parameter Mixture-of-Experts (MoE) model that activates solely 37 billion parameters per token, optimizing computational efficiency without sacrificing capability. Its Mixture-of-Experts (MoE) design dynamically activates solely 37 billion parameters per token (vs. Auxiliary-Loss-Free Load Balancing: Unlike traditional MoE fashions, DeepSeek makes use of dynamic bias adjustments to distribute workloads throughout experts, avoiding efficiency degradation from auxiliary losses. To achieve load balancing amongst completely different specialists within the MoE part, we need to ensure that every GPU processes roughly the identical number of tokens. FP8 Precision: Reduces GPU hours by 40%, chopping pre-coaching costs to 2.788 million H800 GPU hours.
![]() Low-Rank Compression: Compresses KV vectors to 1/16th their original dimension, slashing GPU reminiscence necessities. Efficient Caching: Stores compressed latent vectors during inference, enabling faster token generation. Dynamic Routing: Each token selects 8 out of 256 routing specialists per MoE layer, guaranteeing job-particular processing. Through architectural ingenuity-MoE with dynamic routing, FP8 coaching, and open-source collaboration-DeepSeek delivers GPT-4-stage efficiency at 1/twentieth the associated fee. Memory Savings: FP8 halves reminiscence consumption in comparison with FP16, enabling training on fewer GPUs. Anyone wish to take bets on when we’ll see the primary 30B parameter distributed coaching run? While U.S. chip sanctions have created obstacles, they've additionally forced Chinese firms to change into more resourceful and environment friendly-a pattern that would make them stronger competitors in the long run. The brand new DeepSeek product is a complicated reasoning model most much like OpenAI’s o1 that was launched Monday, Jan. 20. R1 has been compared favorably to the perfect products of OpenAI and Meta while showing to be extra environment friendly, cheaper and doubtlessly made with out relying on probably the most powerful and expensive AI accelerators which are tougher to purchase in China due to U.S. DeepSeek is a new entrant to the AI large-language model arms race involving OpenAI, Facebook mother or father Meta and Google mother or father Alphabet.
Low-Rank Compression: Compresses KV vectors to 1/16th their original dimension, slashing GPU reminiscence necessities. Efficient Caching: Stores compressed latent vectors during inference, enabling faster token generation. Dynamic Routing: Each token selects 8 out of 256 routing specialists per MoE layer, guaranteeing job-particular processing. Through architectural ingenuity-MoE with dynamic routing, FP8 coaching, and open-source collaboration-DeepSeek delivers GPT-4-stage efficiency at 1/twentieth the associated fee. Memory Savings: FP8 halves reminiscence consumption in comparison with FP16, enabling training on fewer GPUs. Anyone wish to take bets on when we’ll see the primary 30B parameter distributed coaching run? While U.S. chip sanctions have created obstacles, they've additionally forced Chinese firms to change into more resourceful and environment friendly-a pattern that would make them stronger competitors in the long run. The brand new DeepSeek product is a complicated reasoning model most much like OpenAI’s o1 that was launched Monday, Jan. 20. R1 has been compared favorably to the perfect products of OpenAI and Meta while showing to be extra environment friendly, cheaper and doubtlessly made with out relying on probably the most powerful and expensive AI accelerators which are tougher to purchase in China due to U.S. DeepSeek is a new entrant to the AI large-language model arms race involving OpenAI, Facebook mother or father Meta and Google mother or father Alphabet.
The magnificent seven contains Alphabet, Amazon, Apple, Meta Microsoft, Nvidia and Tesla, accounting for about $17 trillion of market value between the seven giants. American AI billionaires like Tesla CEO Elon Musk and ScaleAI CEO Alexandr Wang theorize DeepSeek truly owns greater than $1 billion value of Nvidia gear. And most importantly, by displaying that it works at this scale, Prime Intellect is going to bring more attention to this wildly necessary and unoptimized a part of AI research. The company notably didn’t say how a lot it price to prepare its mannequin, leaving out potentially expensive analysis and development prices. Now we now have Ollama running, let’s check out some fashions. In his speech final Tuesday, Trump particularly referred to as out the significance for the U.S. China’s Response to U.S. China’s AI industry has taken a dramatic turn with the rise of DeepSeek, an AI company that overcame U.S. DeepSeek, developed by the Chinese AI research group underneath the umbrella of the quantitative investment firm Huanfang, represents a paradigm shift in massive language models (LLMs). Don’t "buy into the doomsday scenarios currently playing out" about DeepSeek, Bernstein analyst Stacy Rasgon wrote in a Monday word to purchasers, including the "panic over the weekend seems overblown." DeepSeek’s assertion it cost just $5.6 million in computing energy to develop its mannequin is "categorically false," in accordance Rasgon, who said the deceptive determine doesn't account for different "substantial" prices associated to its AI model’s growth.
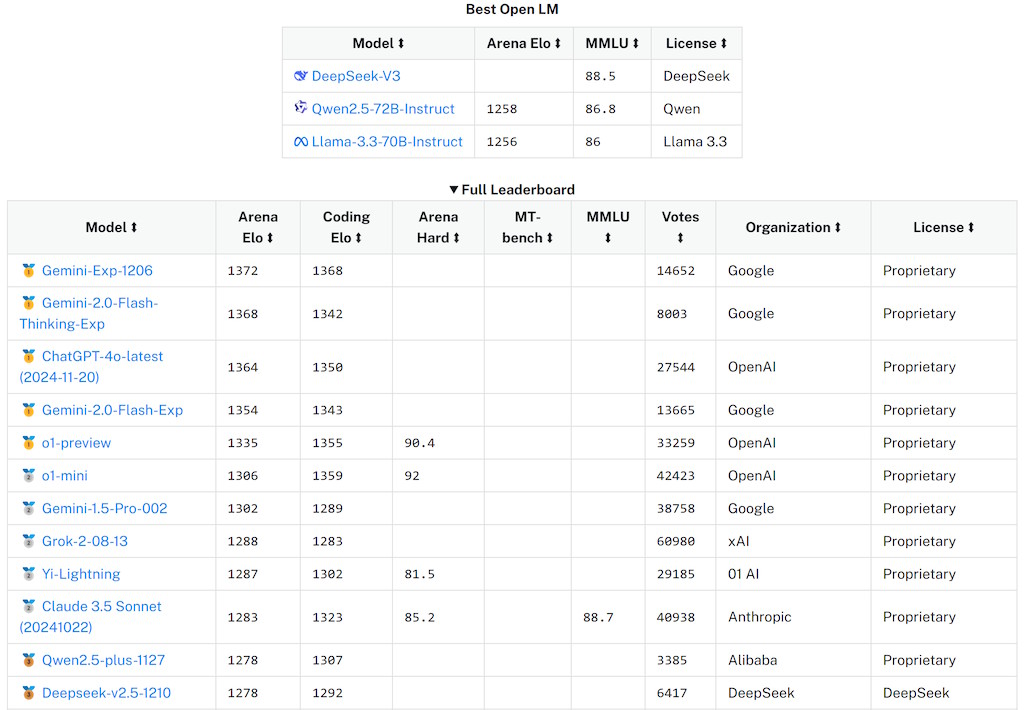 As the controversy round artificial intelligence heats up, DeepSeek’s success is raising questions about the way forward for ديب سيك innovation in the U.S. A Wake-Up Call for the U.S. The Reaction from U.S. When the U.S. imposed bans on the export of advanced chips to China, it was seen as a significant blow to the Chinese tech business. The U.S. export restrictions pressured China to prioritize technological independence, an extended-standing ambition of President Xi Jinping. Skepticism: Some U.S. tech leaders, including Elon Musk, query DeepSeek’s claims about its resource utilization. DeepSeek’s earlier model, V3, unveiled in December, was reportedly educated in two months at a price of US$5.Fifty eight million (RM25.8 million), a fraction of the assets utilized by its bigger rivals, in keeping with SCMP. Combining slicing-edge architectural innovations with value-efficient training strategies, DeepSeek challenges trade giants like OpenAI and Anthropic by delivering state-of-the-art efficiency at a fraction of the price. The selloff stems from weekend panic over last week’s launch from the relatively unknown Chinese agency DeepSeek of its competitive generative AI mannequin rivaling OpenAI, the American agency backed by Microsoft and Nvidia, and its viral chatbot ChatGPT, with deepseek ai notably operating at a fraction of the price of U.S.-based mostly rivals. What Spurred The Stock Panic?
As the controversy round artificial intelligence heats up, DeepSeek’s success is raising questions about the way forward for ديب سيك innovation in the U.S. A Wake-Up Call for the U.S. The Reaction from U.S. When the U.S. imposed bans on the export of advanced chips to China, it was seen as a significant blow to the Chinese tech business. The U.S. export restrictions pressured China to prioritize technological independence, an extended-standing ambition of President Xi Jinping. Skepticism: Some U.S. tech leaders, including Elon Musk, query DeepSeek’s claims about its resource utilization. DeepSeek’s earlier model, V3, unveiled in December, was reportedly educated in two months at a price of US$5.Fifty eight million (RM25.8 million), a fraction of the assets utilized by its bigger rivals, in keeping with SCMP. Combining slicing-edge architectural innovations with value-efficient training strategies, DeepSeek challenges trade giants like OpenAI and Anthropic by delivering state-of-the-art efficiency at a fraction of the price. The selloff stems from weekend panic over last week’s launch from the relatively unknown Chinese agency DeepSeek of its competitive generative AI mannequin rivaling OpenAI, the American agency backed by Microsoft and Nvidia, and its viral chatbot ChatGPT, with deepseek ai notably operating at a fraction of the price of U.S.-based mostly rivals. What Spurred The Stock Panic?
If you enjoyed this write-up and you would certainly such as to obtain even more info regarding ديب سيك kindly go to the web-site.
- 이전글15 Dewalt Tools For Sale Benefits Everyone Needs To Be Able To 25.02.01
- 다음글11 Ways To Completely Redesign Your Retro Cream Fridge Freezer 25.02.01
댓글목록
등록된 댓글이 없습니다.